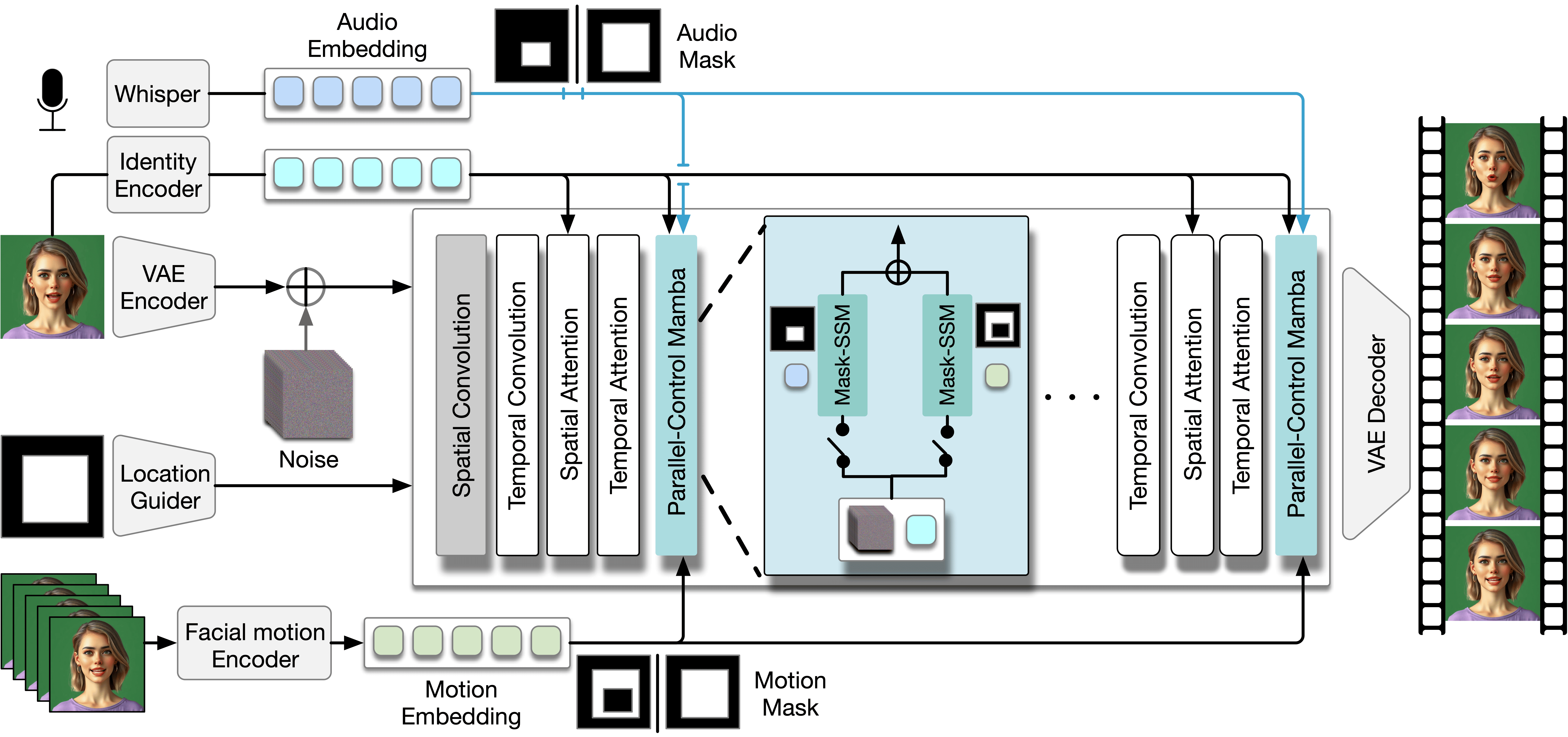
Talking head synthesis is vital for virtual avatars and human-computer interaction. However, most existing methods are typically limited to accepting control from a single primary modality, restricting their practical utility. To this end, we introduce ACTalker, an end-to-end video diffusion framework that support both multi-signals control and single-signal control for talking head video generation. For multiple control, we design a parallel mamba structure with multiple branches, each utilizing a separate driving signal to control specific facial regions. A gate mechanism is applied across all branches, providing flexible control over video generation. To ensure natural coordination of the controlled video both temporally and spatially, we employ the mamba structure, which enables driving signals to manipulate feature tokens across both dimensions in each branch. Additionally, we introduce a mask-drop strategy that allows each driving signal to independently control its corresponding facial region within the mamba structure, preventing control conflicts. Experimental results demonstrate that our method produces natural-looking facial videos driven by diverse signals and that the mamba layer seamlessly integrates multiple driving modalities without conflict.
(For the best viewing experience, please ensure your sound is enabled. If you are not hearing any audio, we recommend using Google Chrome.)