CO2-Net: Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization
Department of Computer Science and Engineering, HKUST, HK
Applied Research Center (ARC), Tencent PCG

Results of our method.
Abstract
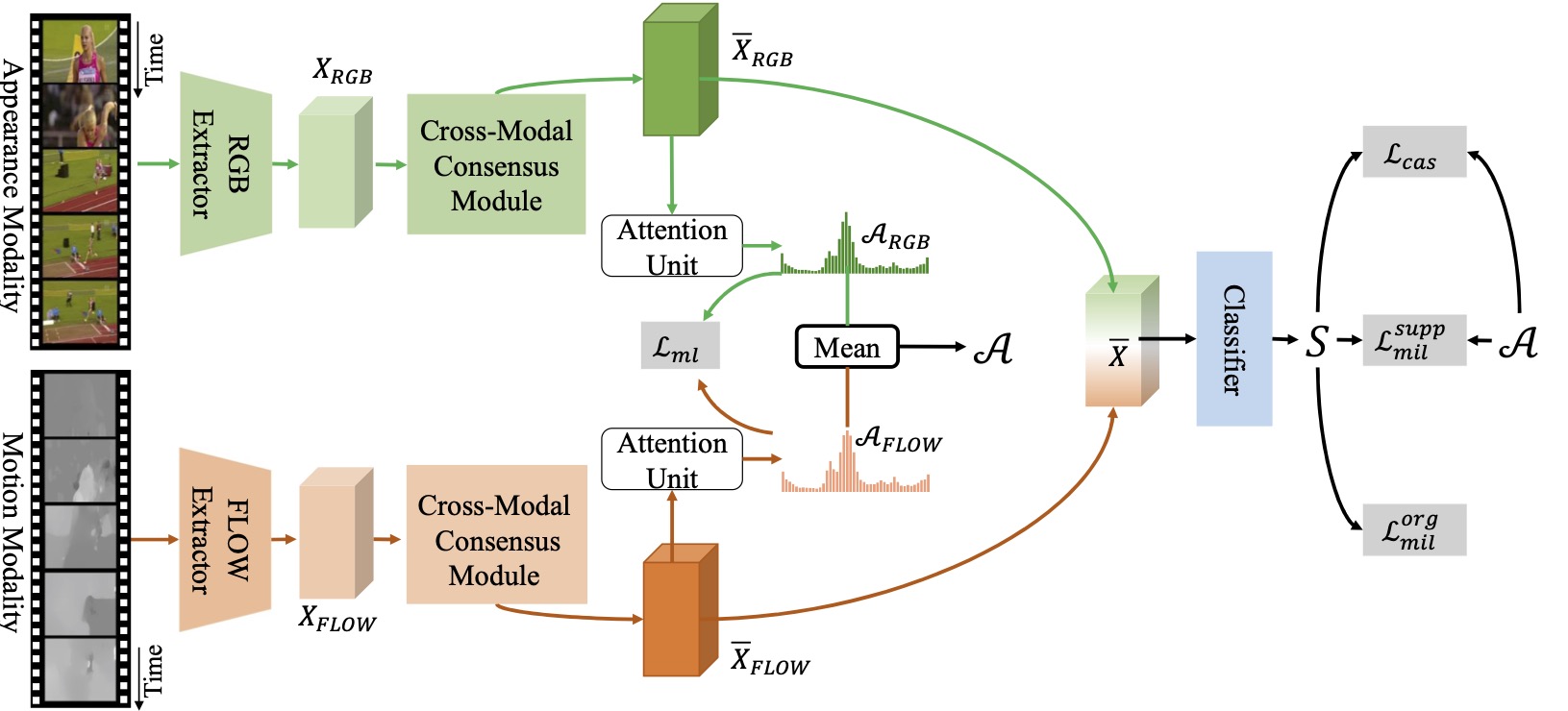
Weakly supervised temporal action localization (WS-TAL) is achallenging task that aims to localize action instances in the givenvideo with video-level categorical supervision. Previous works usethe appearance and motion features extracted from pre-trainedfeature encoder directly,e.g.,feature concatenation or score-levelfusion. In this work, we argue that the features extracted fromthe pre-trained extractors,e.g.,I3D, which are trained for trimmedvideo action classification, but not specific for WS-TAL task, leadingto inevitable redundancy. Therefore, the feature re-calibration isneeded for reducing the task-irrelevant information redundancy. Here, we propose a cross-modal consensus network (CO2-Net) totackle this problem. In CO2-Net, we mainly introduce two identicalproposed cross-modal consensus modules (CCM) that design across-modal attention mechanism to filter out the task-irrelevantinformation redundancy using the global information from themain modality and the cross-modal local information from theauxiliary modality. Moreover, we further explore inter-modalityconsistency, where we treat the attention weights derived from eachCCM as the pseudo targets of the attention weights derived fromanother CCM to maintain the consistency between the predictionsderived from two CCMs, forming a mutual learning manner. Finally,we conduct extensive experiments on two common used temporalaction localization datasets, THUMOS14 and ActivityNet1.2, toverify our method and achieve the state-of-the-art results. Theexperimental results show that our proposed cross-modal consensusmodule can produce more representative features for temporalaction localization.

Testing Datasets
 Thumos14 |
ActivityNet1.2 |
Citation
@inproceedings{hong2021cross,
title={Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization},
author={Fa-Ting Hong, Jia-Chang Feng, Dan Xu, Ying Shan, and Wei-Shi Zheng},
booktitle={ACM MM},
year={2021}
}
Acknowledgement
This project page is learned from the GFP-GAN, thanks to Xintao Wang.
Contact
If you have any question, please contact Fa-Ting Hong at fhongac@cse.ust.hk.